How to Convert Text to Speech Using Python and SpeechGen API from the Console
08-09-2025 , 08-09-2025
These steps will help you set up and use the script to convert text to speech using the SpeechGen.io API.
Download the completed script with files here.
Step 1: Installing Required Python Modules
Make sure you have Python installed. If not, download and install it from the official Python website.
Open the command prompt (cmd) and install the necessary modules:
pip install requests
Step 2: Creating Necessary Files
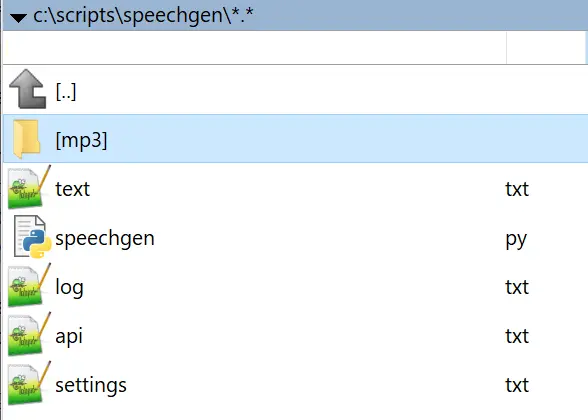
1. Create the directory structure:
mkdir c:\scripts\speechgen
mkdir c:\scripts\speechgen\mp3
2. Create the file text.txt in any directory, such as this one: c:\scripts\speechgen. This file will contain the text that needs to be converted to speech.
3. Create the file api.txt in any directory, such as this one: c:\scripts\speechgen. This file will contain your email and API key, which you can get after registering on the SpeechGen.io website.
Example content of api.txt:
{
"email": "your_email@example.com",
"token": "your_api_token"
}
4. Create the file settings.txt in any directory, such as this one: c:\scripts\speechgen. This file will contain the settings for the speech synthesis. Settings may include voice selection, speed, pitch, and other parameters.
Example content of settings.txt:
'voice'=>'Brian',
'format'=>'mp3',
'speed'=>1.1,
'pitch'=>0.8,
'emotion'=>'good',
'pause_sentence'=>300,
'pause_paragraph'=>400,
'bitrate'=>48000
Step 3: Understanding Methods 1 and 2
Method 1:
Description: Used for converting short texts (up to 2000 characters). The speech synthesis result is returned immediately.
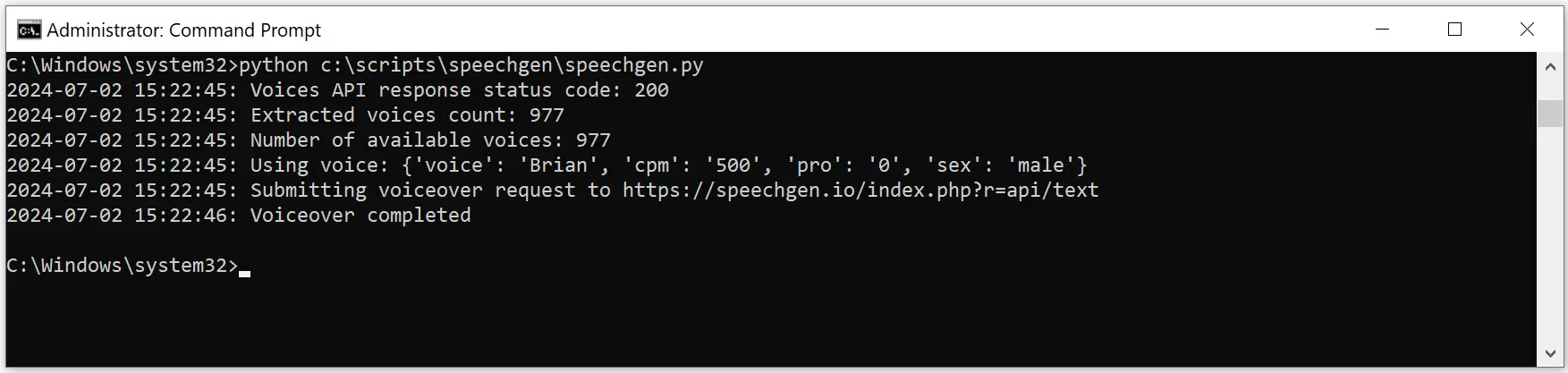
Request URL: https://speechgen.io/index.php?r=api/text
Response URL: The same, the result is returned immediately.
Example request data:
{
"token": "your_api_token",
"email": "your_email@example.com",
"voice": "John",
"text": "Short text to be converted to speech.",
"format": "mp3",
"speed": 1.1,
"pitch": 0.8,
"emotion": "good"
}
Method 2:
Description: Used for converting long texts (over 2000 characters). This method creates a speech synthesis task and returns a task identifier. The script then periodically checks the task status until the result is ready.
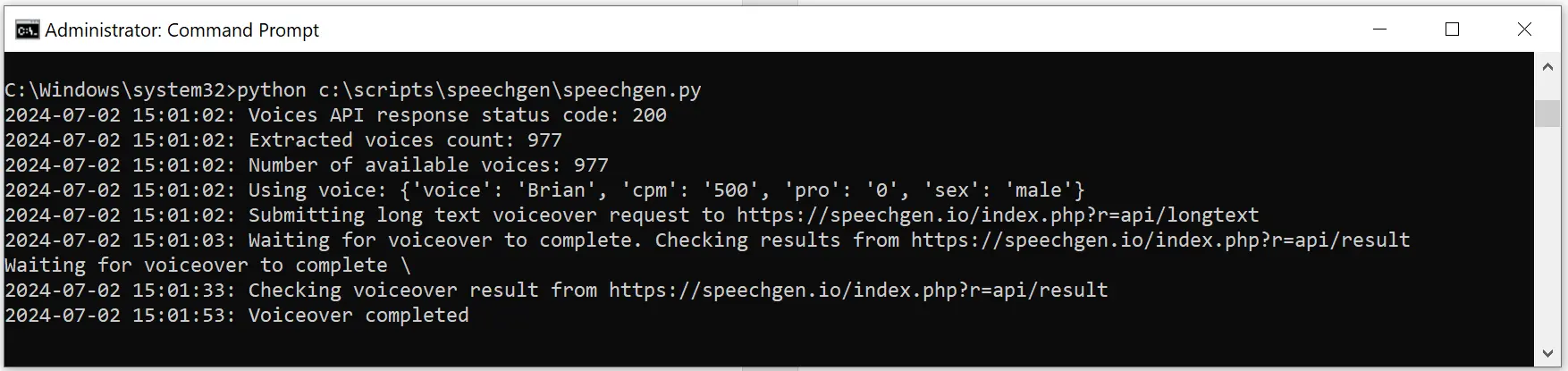
Request URL: https://speechgen.io/index.php?r=api/longtext
Status Check URL: https://speechgen.io/index.php?r=api/result
Example request data:
{
"token": "your_api_token",
"email": "your_email@example.com",
"voice": "John",
"text": "Long text to be converted to speech...",
"format": "mp3",
"speed": 1.1,
"pitch": 0.8,
"emotion": "good"
}
Initial Response:
Response parameters:
{
"id": "1234567",
"status": 0,
"format": "mp3",
"error": "",
"balans": "1000.00"
}
After receiving the task identifier (id), it is necessary to send requests to check the task status every 30-60 seconds until the task status is 1 and the URL for downloading the file is obtained.
Example data for checking task status:
{
"token": "your_api_token",
"email": "your_email@example.com",
"id": 1234567
}
Task Status Response:
Response parameters:
{
"id": "1234567",
"status": 1,
"file": "https://speechgen.io/texttomp3/20240702/p_1234567_63.mp3",
"format": "mp3",
"error": "",
"balans": "900.00"
}
Status values explained:
The status field in the API response indicates the current state of the voiceover task. Here are the possible values:
- 0 - The task is still in process. The voiceover has not yet completed.
- 1 - The task has completed successfully. The file URL for the completed voiceover will be available in the response.
- -1 - An error has occurred. The error message will provide more details about the issue.
Step 4: Running the Script
Save the script below in a file named speechgen.py in the directory c:\scripts\speechgen.
Open the command prompt and run the command:
python c:\scripts\speechgen\speechgen.py
Key Code Snippets
Function to send API request:
def send_request(url, data):
response = requests.post(url, data=data)
return response.json()
Method 1:
if len(text) <= 2000:
url = "https://speechgen.io/index.php?r=api/text"
# Logging the request
log_message(f"Submitting voiceover request to {url}", to_console=True)
log_message(f"Request: {json.dumps({**data, 'text': short_text})}", to_console=False)
# Sending the request and getting the response
response = send_request(url, data)
log_message(f"Response: {json.dumps(response)}", to_console=False)
# Handling the response
if response['status'] == 1:
if 'file' in response and 'format' in response:
file_url = response['file']
file_format = response['format']
file_id = response['id']
file_path = os.path.join(output_folder, f'{file_id}_{voice}.{file_format}')
file_content = requests.get(file_url).content
with open(file_path, 'wb') as file:
file.write(file_content)
log_message("Voiceover completed", to_console=True)
log_message(f"Voiceover completed: {file_path}", to_console=False)
else:
log_message(f"Error: Missing 'file' or 'format' in response. Status: {response['status']}, Error: {response.get('error', 'No error message')}", to_console=True)
else:
log_message(f"Error: {response.get('error', 'Unknown error')}", to_console=True)
Method 2:
else:
url = "https://speechgen.io/index.php?r=api/longtext"
# Logging the request
log_message(f"Submitting long text voiceover request to {url}", to_console=True)
log_message(f"Request: {json.dumps({**data, 'text': short_text})}", to_console=False)
# Sending the request and getting the response
response = send_request(url, data)
log_message(f"Response: {json.dumps(response)}", to_console=False)
if 'id' in response:
task_id = response['id']
result_url = "https://speechgen.io/index.php?r=api/result"
# Waiting before the first status check
log_message(f"Waiting for voiceover to complete. Checking results from {result_url}", to_console=True)
animate_process("Waiting for voiceover to complete", duration=30)
# Checking the task status
while True:
result_data = {
'token': token,
'email': email,
'id': task_id,
}
log_message(f"Checking voiceover result from {result_url}", to_console=True)
result_response = send_request(result_url, result_data)
log_message(f"Result response: {json.dumps(result_response)}", to_console=False)
# Checking if the task is completed
if 'file' in result_response and result_response['status'] == '1':
file_url = result_response['file']
file_format = result_response['format']
file_id = result_response['id']
file_path = os.path.join(output_folder, f'{file_id}_{voice}.{file_format}')
file_content = requests.get(file_url).content
with open(file_path, 'wb') as file:
file.write(file_content)
log_message("Voiceover completed", to_console=True)
log_message(f"Voiceover completed: {file_path}", to_console=False)
break # Exiting the loop after successfully downloading the file
elif result_response['status'] == '-1':
error_message = f"Error: {result_response['error']}"
log_message(error_message, to_console=True)
break
else:
log_message("Voiceover request is still in process...", to_console=True)
animate_process("Processing voiceover request", duration=30)
else:
log_message(f"Error: {response.get('error', 'Unknown error')}", to_console=True)
Full Script
import requests
import json
import time
import os
from datetime import datetime
# Function to read a file
def read_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
return file.read().strip()
# Function to read settings from the settings.txt file
def read_settings(file_path):
settings = {}
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
for line in lines:
key, value = line.strip().split('=>')
settings[key.strip("'")] = eval(value.strip(", "))
return settings
# Function to get the list of voices
def get_voices():
url = "https://speechgen.io/index.php?r=api/voices"
response = requests.get(url)
log_message(f"Voices API response status code: {response.status_code}")
if response.status_code == 200:
try:
voices_data = response.json()
if isinstance(voices_data, dict):
voices = []
for language, voices_list in voices_data.items():
voices.extend(voice for voice in voices_list)
log_message(f"Extracted voices count: {len(voices)}")
return voices
else:
log_message("Error: Unexpected JSON structure")
return []
except json.JSONDecodeError:
log_message("Error decoding JSON response from voices API.")
return []
else:
log_message("Failed to fetch voices from API.")
return []
# Function to send a request via API
def send_request(url, data):
response = requests.post(url, data=data)
return response.json()
# Function for logging
def log_message(message, to_console=True):
log_file = r'c:\scripts\speechgen\log.txt'
timestamp = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
log_entry = f"{timestamp}: {message}"
with open(log_file, 'a', encoding='utf-8') as log:
log.write(log_entry + "\n")
if to_console:
print(log_entry)
# Function for process animation
def animate_process(message, duration=30):
animation = "|/-\\"
end_time = time.time() + duration
idx = 0
while time.time() < end_time:
print(f"\r{message} {animation[idx % len(animation)]}", end="")
time.sleep(0.5)
idx += 1
print()
# Main function
def main():
# File paths
text_file = r'c:\scripts\speechgen\text.txt'
api_file = r'c:\scripts\speechgen\api.txt'
settings_file = r'c:\scripts\speechgen\settings.txt'
output_folder = r'c:\scripts\speechgen\mp3'
# Checking if the settings file exists
if not os.path.exists(settings_file):
log_message(f"Settings file not found: {settings_file}", to_console=True)
return
# Reading the text for speech synthesis
text = read_file(text_file)
# Reading API settings
api_info = json.loads(read_file(api_file))
email = api_info.get("email", "").strip()
token = api_info.get("token", "").strip()
# Reading settings from the settings.txt file
settings = read_settings(settings_file)
# Getting the list of voices
voices = get_voices()
log_message(f"Number of available voices: {len(voices)}")
# Checking the validity of the voice
voice = settings.get('voice', 'John')
matched_voice = next((v for v in voices if v['voice'] == voice), None)
if matched_voice is None:
available_voices = ', '.join([v['voice'] for v in voices])
log_message(f"Error: Voice '{voice}' is not available. Available voices are: {available_voices}")
voice = 'John' # Setting the default voice
log_message(f"Using default voice: {voice}")
else:
log_message(f"Using voice: {matched_voice}")
# Forming the data for the request
data = {
'token': token,
'email': email,
'voice': voice,
'text': text,
}
optional_params = ['format', 'speed', 'pitch', 'emotion', 'pause_sentence', 'pause_paragraph', 'bitrate']
for param in optional_params:
if param in settings:
data[param] = settings[param]
# Shortening the content of the text for logging
short_text = text if len(text) <= 100 else text[:97] + '...'
# Determining the URL based on the length of the text
if len(text) <= 2000:
url = "https://speechgen.io/index.php?r=api/text"
# Logging the request
log_message(f"Submitting voiceover request to {url}", to_console=True)
log_message(f"Request: {json.dumps({**data, 'text': short_text})}", to_console=False)
# Sending the request and getting the response
response = send_request(url, data)
log_message(f"Response: {json.dumps(response)}", to_console=False)
# Handling the response
if response['status'] == 1:
if 'file' in response and 'format' in response:
file_url = response['file']
file_format = response['format']
file_id = response['id']
file_path = os.path.join(output_folder, f'{file_id}_{voice}.{file_format}')
file_content = requests.get(file_url).content
with open(file_path, 'wb') as file:
file.write(file_content)
log_message("Voiceover completed", to_console=True)
log_message(f"Voiceover completed: {file_path}", to_console=False)
else:
log_message(f"Error: Missing 'file' or 'format' in response. Status: {response['status']}, Error: {response.get('error', 'No error message')}", to_console=True)
else:
log_message(f"Error: {response.get('error', 'Unknown error')}", to_console=True)
else:
url = "https://speechgen.io/index.php?r=api/longtext"
# Logging the request
log_message(f"Submitting long text voiceover request to {url}", to_console=True)
log_message(f"Request: {json.dumps({**data, 'text': short_text})}", to_console=False)
# Sending the request and getting the response
response = send_request(url, data)
log_message(f"Response: {json.dumps(response)}", to_console=False)
if 'id' in response:
task_id = response['id']
result_url = "https://speechgen.io/index.php?r=api/result"
# Waiting before the first check
log_message(f"Waiting for voiceover to complete. Checking results from {result_url}", to_console=True)
animate_process("Waiting for voiceover to complete", duration=30)
# Checking the status of the task
while True:
result_data = {
'token': token,
'email': email,
'id': task_id,
}
log_message(f"Checking voiceover result from {result_url}", to_console=True)
result_response = send_request(result_url, result_data)
log_message(f"Result response: {json.dumps(result_response)}", to_console=False)
# Checking if the task is completed
if 'file' in result_response and result_response['status'] == '1':
file_url = result_response['file']
file_format = result_response['format']
file_id = result_response['id']
file_path = os.path.join(output_folder, f'{file_id}_{voice}.{file_format}')
file_content = requests.get(file_url).content
with open(file_path, 'wb') as file:
file.write(file_content)
log_message("Voiceover completed", to_console=True)
log_message(f"Voiceover completed: {file_path}", to_console=False)
break # Exiting the loop after successful file download
elif result_response['status'] == '-1':
error_message = f"Error: {result_response['error']}"
log_message(error_message, to_console=True)
break
else:
log_message("Voiceover request is still in process...", to_console=True)
animate_process("Processing voiceover request", duration=30)
else:
log_message(f"Error: {response.get('error', 'Unknown error')}", to_console=True)
if __name__ == "__main__":
main()